Séance 08 - Comparer
Support de présentation (ouvrir en grand) :
Utilisez les flèches ← et → pour naviguer entre les diapositives.
Sommaire
Plan #
- Qu’est-ce que la fouille de textes ?
- L’enjeu de l’accès au texte : la numérisation
- Ngram Viewer : fonctionnement et utilisation
1. Qu’est-ce que la fouille de textes ? #
La fouille de textes est une fouille de données spécialisée, il s’agit d’extraire des termes ou des expressions d’un corpus de textes pour l’analyse de ces textes. Il peut s’agir de déterminer des relations dans le texte, impossible sans cette technique (numérique).
En lien avec la fouille de textes il y a le traitement automatique des langues (ou NLP pour Natural language processing).
1. Qu’est-ce que la fouille de textes ? #
1.1. Quelques cas d’usage #
- faire une étude linguistique
- chercher une ou des expressions précises dans un corpus
- comparer les occurrences de plusieurs termes/expressions dans un corpus
- comparer plusieurs versions d’un même texte à partir de critères préétablis
1. Qu’est-ce que la fouille de textes ? #
1.2. Le fonctionnement de la fouille de textes #
- disposer d’un corpus interrogeable
- définir une méthode et des outils pour extraire des informations
- réaliser les manipulations et les interprétations
Les étapes :
- constituer le corpus, le délimiter
- analyser le texte : extraire les termes, les expressions, etc.
- interpréter les résultats : extraire les informations des analyses
Deux exemples de fouille de textes : le référencement des sites web, ou encore la gestion des pourriels. Dans les cas, il s’agit de traiter une grande quantité de texte, comprendre ce que le texte signifie et réaliser des actions en conséquence. Dans le cas du référencement web il s’agit de créer des index à partir de nombreux textes structurés (les pages web), alors qu’avec la gestion du spam il s’agit d’identifier les messages considérés comme non pertinents.
D’autres domaines font appel au text mining pour améliorer leurs chaînes de traitement, de la recherche de brevets à la veille en passant par l’analyse de textes biomédicaux pour établir une veille technique.
1. Qu’est-ce que la fouille de textes ? #
1.3. Des outils à disposition #
Pour :
- nettoyer le texte
- transformer le texte en base de données
- interroger le texte
Outils :
- langages de programmation : Python très utilisé dans les DH
- pour nettoyer le texte et déterminer des modèles : des algorithmes
- pour visualiser/analyser/interpréter les résultats : des bibliothèques de code ou des logiciels
Il y a donc différentes tâches à réaliser, des outils existent pour une ou plusieurs de ces tâches.
La question des algorithmes est récurrentes dans la fouille de textes ou le traitement automatique des langues. Mais qu’est-ce qu’un algorithme ?
Aparté : qu’est-ce qu’un algorithme ? #
Un algorithme, c’est tout simplement une façon de décrire dans ses moindres détails comment procéder pour faire quelque chose.
Gérard Berry
La définition de Wikipédia est également très compréhensible : « Un algorithme est une suite finie et non ambiguë d’instructions et d’opérations permettant de résoudre une classe de problèmes » (Source).
Dis autrement, un algorithme est une recette de cuisine : il s’agit d’une série finie d’instructions précises qui permet de traiter des informations en entrée pour obtenir un résultat dans un temps acceptable. Si aujourd’hui les algorithmes nous sont présentés comme des agents indépendants, il s’agit toujours de créations humaines, même si elles sont parfois très très complexes. L’enjeu des algorithmes est de parvenir à modéliser, pour une machine, une action complexe.
Pour terminer sur la question des outils, la TEI (un schéma XML particulier) peut être utilisée pour structurer des textes. Plutôt que de traiter du texte au kilomètre, il devient alors possible de travailler avec un corpus sémantisé.
Quelques logiciels permettent de réaliser toutes ces tâches en même temps, comme Voyant-Tools que nous découvrirons à la prochaine séance.
2. L’enjeu de l’accès au texte : la numérisation #
2. L’enjeu de l’accès au texte : la numérisation #
2.1. Pour fouiller : disposer de textes #
- qu’est-ce qu’un texte ?
- distinction prise de vue (image) et texte interrogeable (format texte/plein texte)
- texte structuré
2. L’enjeu de l’accès au texte : la numérisation #
2.2. Des corpus numérisés : qui ? #
- universités et bibliothèques nationales
- initiatives indépendantes
Qui numérise tous ces documents ? Numériser des textes est complexe et coûteux, il faut à la fois disposer des textes originaux (principalement des livres), avoir du matériel pour la prise de vue, des conditions adéquates pour ne pas abîmer les documents et enfin les logiciels et les savoir faire pour le traitement des documents.
Les premières structures qui commencent à numériser des documents sont des universités et des bibliothèques, principalement pour des questions de sauvegarde, puis pour des questions de consultation des documents (plus facile même avec des CD-ROM, et en évitant de trop manipuler des documents vieillissants) et enfin pour des questions de recherche dans les documents.
La Bibliothéque nationale de France a été par exemple l’une des premières à débuter une importante campagne de numérisation avec Gallica, après la Bibliothèque du Congrès aux États-Unis ou le Projet Gutenberg, mais avant Google Books.
Google Books ou Google Livres est un projet de très grande envergure qui débute en 2002 et qui va créer de nombreux débats :
- Google va tenter d’établir des partenariats avec des bibliothèques publiques ou universitaires, proposant une numérisation presque gratuite contre l’ajout de ces documents dans sa base (avec un embargo) ;
- Google va numériser des fonds d’éditeurs sans leur accord, provoquant de nombreux procès.
Il existe aussi des initiatives dites indépendantes, qui ne dépendent pas d’organismes publics et qui sont à but non lucratif : outre le projet Gutenberg, Archive.org est un très bon exemple de tentative de numériser largement au profit de toutes et tous.
2. L’enjeu de l’accès au texte : la numérisation #
2.3. Des corpus numérisés : comment ? #
Quelques étapes nécessaires :
- référencement des documents
- prise de vue (photographie)
- reconnaissance optique des caractères
- zonage du texte et structuration
Petite exploration de comment numériser un texte en plusieurs étapes détaillées ci-dessous :
- le référencement des documents : il faut d’abord savoir quoi numériser, et cela n’est possible qu’à condition de disposer d’une base de données des références des documents concernés. Donc une sorte de catalogue qui comporte des informations primordiales : les métadonnées des documents mais aussi des informations sur les propriétés du document (nombre de pages par exemple). La constitution d’un catalogue est une tâche complexe et longue, mais heureusement les informations sont désormais souvent mutualisées ;
- la prise de vue consiste à prendre en photo les différentes pages d’un document ou d’un livre, et plusieurs paramètres sont à prendre en compte : la qualité de la photo (qualité qui a beaucoup évolué ces 50 dernières années (avec le passage de l’argentique au numérique notamment), le fait que le document est mis à plat, etc. Une prise de vue ne permet pas de faire des requêtes sur un texte, mais uniquement de le consulter autrement que via l’exemplaire analogique. Le mode image permet toutefois de prévoir d’autres traitements par la suite ;
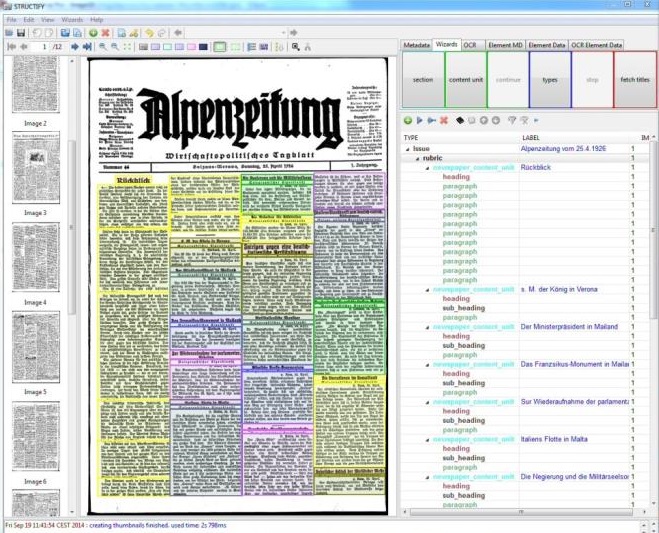
- la reconnaissance optique des caractères (ou OCR) est une opération qui consiste à transformer une image en texte. Outre le fait de pouvoir reconnaître les différents caractères typographiques dans différentes langues, il s’agit aussi d’être en mesure d’attribuer des coordonnées à chaque portion de texte par rapport à l’image afin de pouvoir ensuite développer des fonctionnalités de calques (le texte océrisé vient se placer sur l’image pour afficher des termes recherchés ou sélectionnés) ;
- le zonage du texte et la structuration sont des étapes distinctes qui permettent d’aller au-delà de la simple conversion textuelle d’une image. Ce sont souvent des opérations difficilement automatisables, car elles nécessitent une bonne interprétation du document original. Le zonage du texte consiste en une description des blocs de textes : décrire quel est le type de texte et le placer dans une arborescence logique. La structuration est une opération d’encodage qui consiste à qualifier tout type de texte : niveaux de titres, emphases, listes, citations, noms de personnes ou de lieux, etc.
La numérisation ne se réduit donc pas à une prise de vue ou à une reconnaissance optique de caractères !
3. Ngram Viewer : fonctionnement et utilisation #
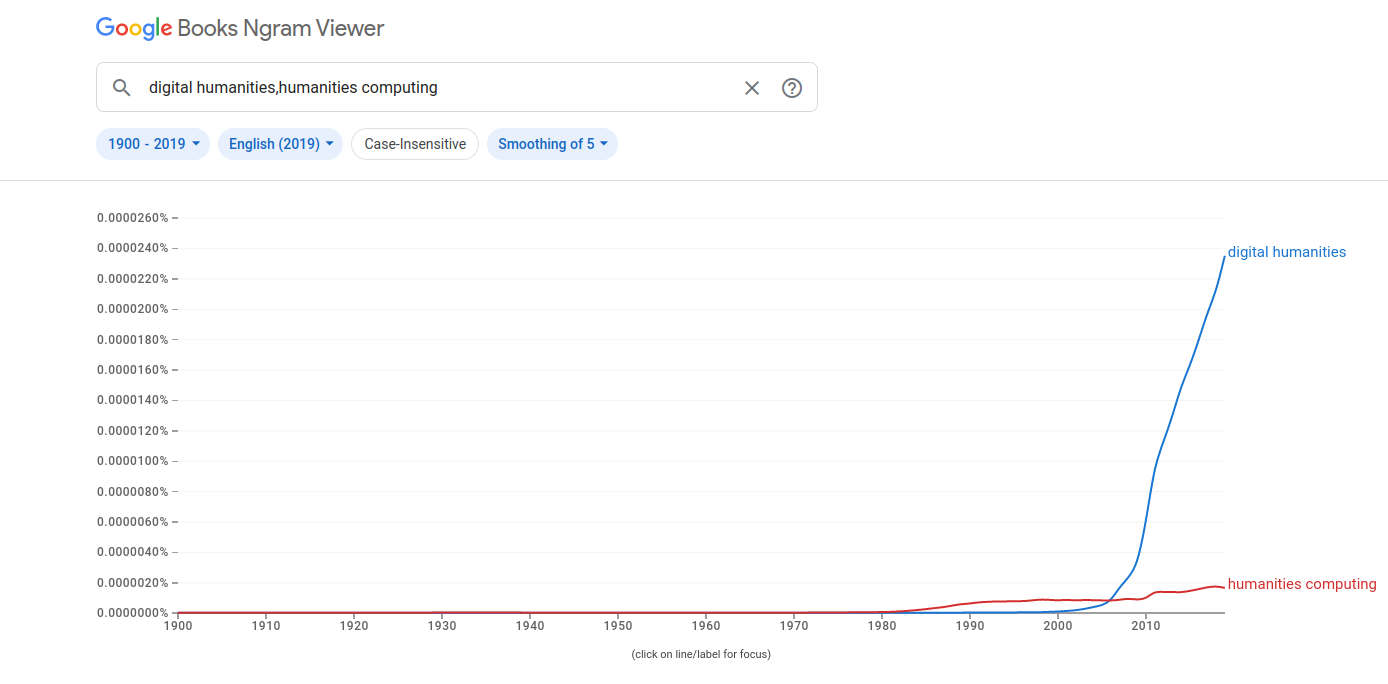
Le cas de notre article :
Attention il faut replacer l’article dans son époque : en 2011 de nombreux corpus étaient disponibles mais avec des outils de recherche moins performants qu’aujourd’hui, et surtout de tailles plus modestes.
Jean-Michel Le Bot explore des corpus de textes de François-René de Chateaubriand pour retrouver une expression qui lui est attribuée. L’auteur explique qu’il est difficile de retrouver la trace d’une phrase en particulier, et pour cela il va utiliser Google Books Ngram Viewer pour tenter de retrouver la trace dans un corpus assez important. L’affichage des résultats sur un graphe permet de prendre la mesure du nombre d’occurrences d’une expression à travers le temps et à travers des corpus très divers. Si Ngram Viewer est intéressant pour appréhender des grands corpus de textes, encore faut-il en faire une analyse plus poussée en ayant accès aux documents sources (ce que ne permet pas totalement Google Books).
Jean-Michel Le Bot montre la limite de Ngram Viewer, limite qu’il est possible aujourd’hui de lever en partie avec l’utilisation de techniques plus puissantes et plus précises. Ces techniques se sont fortement développées depuis une dizaine d’années, avec le développement de ce qu’on appelle l’intelligence artificielle.
3. Ngram Viewer : fonctionnement et utilisation #
3.1. Un outil de fouille de textes accessible #
Un outil d’analyse de textes pour observer des tendances ou des modélisations.
- un corpus de plusieurs millions de livres
- une interface très facile d’accès
- des options de recherche intéressante
3. Ngram Viewer : fonctionnement et utilisation #
3.2. Les dessous de Ngram Viewer #
- un corpus numérisé
- des textes sous forme de bases de données interrogeables
- des algorithmes et des règles d’interprétation
3. Ngram Viewer : fonctionnement et utilisation #
3.3. Exercices #
Pour ces exercices vous pouvez vous aider de l’aide disponible sur cette page : https://books.google.com/ngrams/info
- chercher les occurrences de « livre » dans le corpus français
- comparer les différentes occurrences des termes « livre » et « document » dans le corpus français depuis 1500
- comparer l’usage des expressions « édition savante » et « édition scientifique » toujours dans le corpus français
- comparer les expressions « digital humanities », « humanities computing » et « linguistic computing » dans les corpus de langue anglaise
- comparer l’utilisation du terme « édition » dans le corpus français avec celui de « publishing » dans le corpus anglais